Log Strata — Redefining Observability with Infra Monitor


Introduction
In an era dominated by cloud-native applications, observability has emerged as the backbone of modern software systems. It goes beyond traditional monitoring, focusing on understanding and improving application performance in real-time. The Log Strata Infra Monitor Challenge by STGI empowers developers to embrace this transformation by designing their own observability platform — a blend of creativity, technical ingenuity, and problem-solving.
This isn’t just about coding; it’s about crafting a solution that addresses the ever-evolving complexities of cloud infrastructure. Let’s break down the journey of building an observability platform from scratch.

The Mission
The challenge is deceptively simple yet profound: Build a Cloud Monitoring Tool that collects, processes, and visualizes logs and metrics from a Kubernetes cluster. This requires blending multiple disciplines — DevOps, backend engineering, and UI/UX design.
Core Requirements
Kubernetes Cluster: Deployed locally using Minikube.
Applications: Two apps powered by PostgreSQL and MySQL databases.
Log Collection: Tools like Fluent Bit, FluentD, or Logstash.
Backend Service: Process logs and metrics, storing them in a time series database (InfluxDB).
Custom Dashboard: A web-based interface to visualize data with search and filtering capabilities.

Why This Challenge Matters
Modern cloud systems generate an overwhelming amount of data, making it crucial to design systems that don’t just monitor but also make sense of this data. Observability platforms serve as the eyes and ears of organizations, helping teams:
Detect anomalies in real-time.
Optimize performance through actionable insights.
Enhance reliability by identifying root causes faster.
STGI’s challenge enables participants to tackle these real-world problems in a simulated environment, laying the foundation for impactful solutions in production-scale systems.

How to Build Your Infra Monitor

Step 1: Laying the Foundation

Docker, Kubectl and Minikube Setup
Start with Docker, the building block of containerized environments, and Minikube, which brings Kubernetes to your local machine. Together, they form the staging ground for your platform.
Install Docker :
You can refer installation from here : https://medium.com/@sugam.arora23/docker-unboxed-your-complete-guide-to-installation-on-ubuntu-and-windows-5d367a554afe
Install Kubectl :
You can refer installation from here : https://medium.com/@sugam.arora23/effortlessly-install-kubectl-on-ubuntu-and-windows-your-ultimate-guide-to-kubernetes-mastery-14752b338dde
Install Minikube :
You can refer installation from here : https://medium.com/@sugam.arora23/minikube-setup-guide-a-seamless-experience-on-windows-and-linux-a37cec913e73
Step 2: Deploying the Applications

Deploy two sample applications with PostgreSQL and MySQL backends. Each app represents a microservice within the ecosystem. Ensure proper database connections and verify application logs post-deployment.
Setting Up Kubernetes Deployments for app-1 and app-2
Prerequisites
Ensure Minikube is set up and running on your system (Windows or Ubuntu).
S 1: Clone Sample Applications
- Create Project Directories
mkdir ~/postgresql
mkdir ~/mysql
cd ~/postgresql
cd ~/mysql
2. Clone the Applications Replace <url-for-app-1> and <url-for-app-2> with the actual URLs of your applications.
git clone https://github.com/tanishsummit/PyEditorial
git clone https://github.com/manjillama/docker-node-crud-mysql
S 2: Create Kubernetes Deployments and Services
1. Create Deployment and Service for MySQL (app-1)
- Create YAML File for MySQL Deployment
touch mysql-deployment.yaml
2. Add the Following YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
3. Apply the YAML File
kubectl apply -f mysql-deployment.yaml
2. Create Deployment and Service for PostgreSQL (app-2)
- Create YAML File for PostgreSQL Deployment
touch postgresql-deployment.yaml
2. Add the Following YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
spec:
selector:
matchLabels:
app: postgres
strategy:
type: Recreate
template:
metadata:
labels:
app: postgres
spec:
containers:
- image: postgres:9.6
name: postgres
env:
- name: POSTGRES_PASSWORD
value: password
ports:
- containerPort: 5432
name: postgres
---
apiVersion: v1
kind: Service
metadata:
name: postgres
spec:
ports:
- port: 5432
selector:
app: postgres
3. Apply the YAML File
kubectl apply -f postgresql-deployment.yaml
3. Create Deployments and Services for Applications
a. For App-1 (Connected to MySQL)
- Create YAML File for App-1 Deployment
touch app-1-deployment.yaml
2. Add the Following YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-1
spec:
selector:
matchLabels:
app: app-1
template:
metadata:
labels:
app: app-1
spec:
containers:
- name: app-1
image: <app-1-docker-image>
ports:
- containerPort: 8080
env:
- name: MYSQL_HOST
value: mysql
- name: MYSQL_USER
value: root
- name: MYSQL_PASSWORD
value: password
---
apiVersion: v1
kind: Service
metadata:
name: app-1
spec:
type: NodePort
selector:
app: app-1
ports:
- port: 8080
targetPort: 8080
nodePort: 30001
3. Apply the YAML File
kubectl apply -f app-1-deployment.yaml
b. For App-2 (Connected to PostgreSQL)
- Create YAML File for App-2 Deployment
touch app-2-deployment.yaml
2. Add the Following YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-2
spec:
selector:
matchLabels:
app: app-2
template:
metadata:
labels:
app: app-2
spec:
containers:
- name: app-2
image: <app-2-docker-image>
ports:
- containerPort: 8081
env:
- name: POSTGRES_HOST
value: postgres
- name: POSTGRES_USER
value: postgres
- name: POSTGRES_PASSWORD
value: password
---
apiVersion: v1
kind: Service
metadata:
name: app-2
spec:
type: NodePort
selector:
app: app-2
ports:
- port: 8081
targetPort: 8081
nodePort: 30002
3. Apply the YAML File
kubectl apply -f app-2-deployment.yaml
S 3: For Logger Hackathon
- Pull the Docker Image (Optional)
docker pull tjain598/logger-hackathon:latest
2. Verify the image:
docker images
3. Create YAML File for Logger Hackathon Deployment
touch logger-hackathon-deployment.yaml
4. Add the Following YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: logger-hackathon
spec:
selector:
matchLabels:
app: logger-hackathon
template:
metadata:
labels:
app: logger-hackathon
spec:
containers:
- name: logger-hackathon
image: tjain598/logger-hackathon:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: logger-hackathon
spec:
type: NodePort
selector:
app: logger-hackathon
ports:
- port: 80
targetPort: 80
nodePort: 30003
5. Apply the YAML File
kubectl apply -f logger-hackathon-deployment.yaml
S 4: Accessing the Applications
Use the following commands to access the applications via Minikube:
minikube service app-1
minikube service app-2
minikube service logger-hackathon
You should now be able to access app-1, app-2, and the Logger Hackathon application on your local Kubernetes cluster, connected to their respective services.
S 5 : Verify Logs or Output for Logger App
- Check Pod Logs
kubectl logs <logger-pod-name>
Replace <logger-pod-name> with the actual pod name obtained from:
kubectl get pods
2. Describe Deployment (Optional)
kubectl describe deployment logger-app
Caution : There will be many deployment issues alongside so it is important to understand troubleshooting issues. You can refer some of the deployment issues we faced from the following :
Step 3: Mastering Log Collection

Logs are the pulse of any system, providing invaluable insights into its health and behavior. Use Fluent Bit, FluentD, or Logstash to collect logs from Kubernetes pods and forward them to your backend service. Since we had a monolithic service so we decided to go ahead with Fluent Bit as it is most efficient, resource-friendly, and scalable solution for log collection and processing.
Key Components of Fluent Bit
1. Input Plugins
Input plugins define where Fluent Bit will collect logs from.
Common Sources: Files, TCP, Syslog, Tail (files), Kubernetes, and Docker.
Example: To collect container logs:
[INPUT] Name tail Path /var/log/containers/*.log Tag kube.*
2. Filters
Filters transform or enrich log data before it is forwarded.
- Example: Adding Kubernetes metadata to logs.
[FILTER] Name kubernetes Match kube.* Merge_Log On
3. Output Plugins
Output plugins define where the logs are sent.
Common Destinations: Elasticsearch, stdout, AWS S3, and Kafka.
Example: Forward logs to stdout.
[OUTPUT] Name stdout Match *
Deploying Fluent Bit in Kubernetes
To efficiently collect logs in a Kubernetes cluster, Fluent Bit is typically deployed as a DaemonSet, ensuring a logging agent runs on each node. Here’s a detailed breakdown of the required configuration.
1. ConfigMap
A ConfigMap stores Fluent Bit’s configuration. Below is an example configuration to collect container logs, system logs, and enrich logs with Kubernetes metadata:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: default
labels:
app: fluent-bit
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
[INPUT]
Name tail
Path /var/log/pods/*/*/*.log
Exclude_Path /var/log/pods/*/*fluent-bit*.log, /var/log/pods/*/*coredns*.log, /var/log/pods/*/*kube-controller-manager*.log, /var/log/pods/*/*storage-provisioner*.log, /var/log/pods/*/*kube-scheduler*.log, /var/log/pods/*/*kube-proxy*.log, /var/log/pods/*/*kube-apiserver*.log, /var/log/pods/*/*etcd*.log
Parser docker
Tag kube.*
Refresh_Interval 5
Mem_Buf_Limit 5MB
Skip_Long_Lines On
DB /var/log/flb_kube.db
[FILTER]
Name kubernetes
Match kube.*
Merge_Log On
Keep_Log On
K8S-Logging.Parser On
K8S-Logging.Exclude On
[FILTER]
Name geoip
Match kube.*
Key ip_address
Add_Field true
Include city_name,country_code
[FILTER]
Name record_transformer
Match kube.*
Record new_time ${time}
Time_Format "%Y-%m-%d %H:%M:%S"
[FILTER]
Name grep
Match kube.*
Regex log "ERROR|WARN|INFO"
[FILTER]
Name lua
Match kube.*
script extract_fields.lua
call extract_fields
[FILTER]
Name grep
Match kube.*
Regex kubernetes.pod_name nginx.*
[FILTER]
Name grep
Match kube.*
Regex kubernetes.namespace_name production.*
[FILTER]
Name grep
Match kube.*
Regex kubernetes.labels.app webapp.*
[OUTPUT]
Name influxdb
Match *
Host influxdb
Port 8086
bucket SegFault
org STGI
sequence_tag _seq
http_token 7ETF8X3ZThuQrarZxNeHIsa4QmqjEjmgjJzDQY9PnqegvnM884YbpzDOUolunsn29LxX8FRW1sQPb822-25KrA==
parsers.conf: |
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep On
extract_fields.lua: |
function extract_fields(tag, timestamp, record)
-- Custom logic to extract additional fields from the log
return 1, timestamp, record
end
-- Calculate CPU utilization as a percentage
if total_time > 0 then
cpu_utilization = (active_time / total_time) * 100
else
cpu_utilization = 0
end
-- Add the CPU utilization to the log record
record["cpu_utilization"] = cpu_utilization
return 1, timestamp, record
end
2. DaemonSet
The DaemonSet ensures Fluent Bit runs on all nodes in the cluster.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: default
labels:
app: fluent-bit
spec:
selector:
matchLabels:
name: fluent-bit
template:
metadata:
labels:
name: fluent-bit
spec:
serviceAccountName: fluent-bit
containers:
- name: fluent-bit
image: fluent/fluent-bit:latest
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /fluent-bit/etc/
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluent-bit-config
3. RBAC
RBAC (Role-Based Access Control) in Fluent Bit is used to grant the necessary permissions for Fluent Bit to access Kubernetes resources securely. Fluent Bit uses these permissions to enrich log data with metadata from Kubernetes, such as pod names, namespaces, labels, and annotations.
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluent-bit
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluent-bit-read
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluent-bit-read
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluent-bit-read
subjects:
- kind: ServiceAccount
name: fluent-bit
namespace: kube-logging
Accessing Logs
Fluent Bit uses the following paths to access logs in a Kubernetes environment:
Container Logs:
/var/log/containers/*.logDocker Logs:
/var/lib/docker/containers/*/*.logSystem Logs:
/var/log/*.log
Example Configuration:
[INPUT]
Name tail
Path /var/log/containers/*.log
Tag kube.containers.*
Advanced Use Cases
1. Forwarding Logs to Elasticsearch
To forward logs to Elasticsearch:
[OUTPUT]
Name es
Match *
Host elasticsearch-host
Port 9200
Index fluent-bit
2. Using Custom Parsers
Fluent Bit supports parsers for custom log formats. Example parser for JSON logs:
[PARSER]
Name json
Format json
3. Security
Use RBAC roles to restrict access to Kubernetes resources.
Mount sensitive directories as read-only.
Best Practices
Specify Versions: Avoid using
latestin Docker images; use a specific version.Use Dedicated Namespace: Deploy Fluent Bit in a separate namespace like
kube-logging.Monitor Performance: Regularly check resource usage and optimize configurations for high throughput.
Test Configurations: Test Fluent Bit in a staging environment before deploying to production.
Step 4: Building the Brains — The Backend

The problem statement mentioned using a time series database and no better than InfluxDB as the backend for Fluent Bit, it serves as a time-series database to store log data, metrics, or other telemetry collected by Fluent Bit. Configuring Fluent Bit to use InfluxDB involves ensuring proper setup, enabling seamless integration, and following best practices to store and query log data effectively. It is a robust time series database, to store the logs and metrics. The reason for using InfluxDB is its capability to handle high-velocity data like logs and metrics, while making it easy to query and analyze.
1. Understanding InfluxDB
InfluxDB is a high-performance time-series database designed for storing and querying time-stamped data. Fluent Bit can forward log and metric data to InfluxDB, which can then be used for analysis, visualization, or further processing.
Key Features:
Stores data as time-series points with associated fields and tags.
Optimized for high ingest rates.
Integrates with visualization tools like Grafana.
2. Setting Up InfluxDB for Fluent Bit
S 1: Install InfluxDB
- Docker-based Installation:
docker run -d --name influxdb -p 8086:8086 influxdb:2.0
- Binary Installation: Download and install from InfluxDB downloads page.
S 2: Create a Database and Token
- InfluxDB v1.x: Create a database for Fluent Bit logs:
influx > CREATE DATABASE fluentbit_logs
InfluxDB v2.x:
Create a bucket using the InfluxDB UI or CLI:
influx bucket create -n fluentbit_logs -o your-org
3. Configuring Fluent Bit to Use InfluxDB
To send data to InfluxDB, Fluent Bit uses the InfluxDB output plugin.
S 1: Add the InfluxDB Output Plugin
Update the Fluent Bit configuration file (fluent-bit.conf):
[OUTPUT]
Name influxdb
Match *
Host <INFLUXDB_HOST>
Port <INFLUXDB_PORT>
Database fluentbit_logs
Org your-org # For InfluxDB v2.x
Bucket fluentbit_logs # For InfluxDB v2.x
Token <INFLUXDB_TOKEN> # For InfluxDB v2.x
Sequence_Tag sequence_id # Optional, used for series ordering
TLS On # Enable TLS for secure connections
Verify Off # Skip TLS certificate verification
Time_Precision ms # Use millisecond precision for timestamps
Replace <INFLUXDB_HOST>, <INFLUXDB_PORT>, and <INFLUXDB_TOKEN> with your InfluxDB details.
S 2: Set the Input Plugin
Ensure you have an input plugin to collect logs or metrics. For example, if collecting logs from Kubernetes:
[INPUT]
Name tail
Path /var/log/containers/*.log
Tag kube.*
DB /var/log/fluentbit.db
Mem_Buf_Limit 5MB
4. Storing and Querying Data in InfluxDB
InfluxDB organizes data using:
Measurements: Tables in a relational database context.
Tags: Indexed metadata for efficient querying.
Fields: Actual data points (not indexed).
Timestamps: Every record must have a time.
5. Best Practices
Optimize Fluent Bit Output
Use
Tagin Fluent Bit to organize logs by namespace, pod, or other attributes.Use compression to reduce the size of logs sent to InfluxDB.
InfluxDB Performance Tips
Limit the number of fields per measurement to avoid performance degradation.
Use tags for frequently queried data.
Aggregate data before querying or visualization to reduce load.
Integrate with Visualization Tools
Visualize InfluxDB data with tools like Grafana:
Add InfluxDB as a data source in Grafana.
Create dashboards to display logs and metrics using graphs and tables.
Secure the Integration
Use API tokens for authentication in InfluxDB v2.x.
Enable TLS for secure data transfer between Fluent Bit and InfluxDB.
6. Example End-to-End Workflow
Collect Logs: Fluent Bit collects logs from Kubernetes pods.
Enrich Logs: Metadata from Kubernetes is added (e.g., namespace, pod labels).
Send to InfluxDB: Logs are forwarded to InfluxDB with tags for efficient querying.
Store and Query: Logs are stored in InfluxDB and queried for debugging or monitoring.
Visualize: Use Grafana to visualize logs for insights.
7. Troubleshooting Tips
- Connection Issues:
Ensure Fluent Bit’s Host and Port match InfluxDB's settings.
Check network access between Fluent Bit and InfluxDB.
- Data Not Showing:
Verify the Match directive in Fluent Bit matches the input tags.
Check Fluent Bit logs for errors.
- InfluxDB High Load:
Use batching in Fluent Bit to reduce write operations:
Batch_Size 500 Flush_Interval 5
For backend we used spring boot . Spring Boot uses SLF4J with Logback as the default logging framework. By default, logs are written to the console, but you can configure Spring Boot to log to files or remote systems. Fluent Bit can collect logs from these files or from the standard output (stdout) and send them to a backend like InfluxDB, Elasticsearch, or a log management system.
Step 5: Crafting the Visual Interface

Your dashboard is where the magic happens — a place where raw data transforms into meaningful insights. We built a custom web-based dashboard using ReactJS. The interface should allow users to:
Search logs with keywords or time filters.
Visualize data through graphs, charts, and tables.
Track trends with real-time metric displays.
Key Design Principles:
Keep it minimalistic yet informative.
Ensure it’s responsive for mobile and desktop users.
Prioritize interactivity with dynamic filters and widgets.
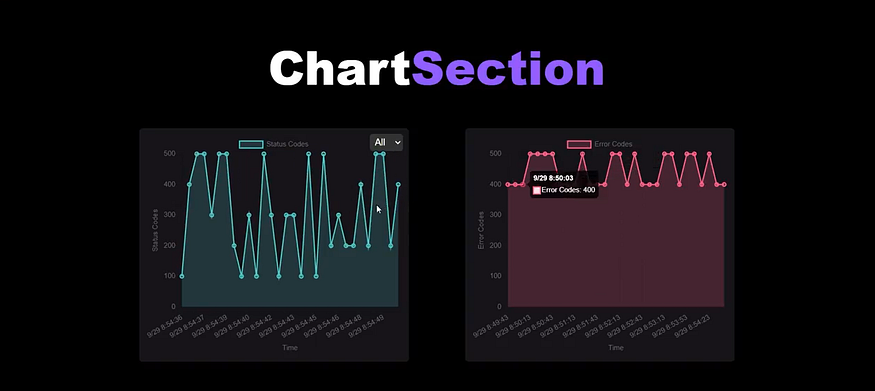
1. Key Metrics Visualized on the Dashboard
1.1 Error Rates
- Purpose: Error rate monitoring allows you to track the number of errors occurring within a specified period, such as HTTP 5xx responses, application errors, or failed requests.
Visualization:
Line Chart: To track error rates over time.
Bar Chart: Comparing error rates per endpoint or service.
Error Heatmap: To show periods of high error occurrence, highlighting potential issues.
Data Sources:
Logs or metrics from the backend, possibly integrated via Fluent Bit or a logging tool like Sentry.
Metrics from API responses (status codes).
1.2 Database Query Performance
- Purpose: Database performance metrics are crucial for understanding how efficiently queries are being executed, the time taken, and any bottlenecks.
Visualization:
Bar Chart or Line Graph: Displaying the average query execution time over time.
Pie Chart: Visualizing query distribution by type (SELECT, INSERT, UPDATE, DELETE).
Heatmap: Indicating peak database load periods.
Data Sources:
Collected from the backend via database logs or query performance tools like New Relic or Prometheus.
Database monitoring tools can expose this data through APIs.
1.3 Traffic and Resource Usage
- Purpose: Traffic and resource usage help you monitor how much load the application is handling and how efficiently resources (CPU, memory, bandwidth) are utilized.
Visualization:
Line Charts: Displaying real-time traffic and resource usage (CPU, memory, bandwidth).
Gauge Charts: For real-time indicators of resource usage such as CPU load or memory consumption.
Area Chart: Showing the correlation between traffic spikes and resource consumption.
Data Sources:
Prometheus, Grafana, or AWS CloudWatch can be used for real-time monitoring of infrastructure metrics.
Web server logs (nginx, apache) and performance monitoring tools.
2. Building the Dashboard in ReactJS
To build a sophisticated and user-friendly dashboard in ReactJS, you’ll need to break it down into components that handle the rendering of the different visualizations. Here’s how you can structure it:
2.1 Project Structure
/src
/components
/Dashboard
Dashboard.js
/ErrorRateChart
ErrorRateChart.js
/DbPerformanceChart
DbPerformanceChart.js
/TrafficUsageChart
TrafficUsageChart.js
/services
metricsService.js // Handles API calls to fetch data
/utils
chartUtils.js // Contains utility functions for data processing and chart formatting
/App.js
/index.js
2.2 Example Code for Dashboard (ReactJS)
Here’s a simplified example of how the dashboard structure might look:
Dashboard.js
import React, { useState, useEffect } from 'react';
import ErrorRateChart from './ErrorRateChart';
import DbPerformanceChart from './DbPerformanceChart';
import TrafficUsageChart from './TrafficUsageChart';
import { getMetrics } from '../../services/metricsService';
const Dashboard = () => {
const [metricsData, setMetricsData] = useState({
errorRates: [],
dbPerformance: [],
trafficUsage: [],
}); useEffect(() => {
const fetchData = async () => {
const data = await getMetrics();
setMetricsData(data);
};
fetchData();
}, []); return (
<div className="dashboard">
<h1>Project Metrics Dashboard</h1>
<div className="chart-container">
<ErrorRateChart data={metricsData.errorRates} />
<DbPerformanceChart data={metricsData.dbPerformance} />
<TrafficUsageChart data={metricsData.trafficUsage} />
</div>
</div>
);
};export default Dashboard;
2.3 Example Chart Component (ErrorRateChart.js)
import React from 'react';
import { Line } from 'react-chartjs-2';
const ErrorRateChart = ({ data }) => {
const chartData = {
labels: data.map(item => item.timestamp), // e.g., time intervals
datasets: [
{
label: 'Error Rate',
data: data.map(item => item.errorCount), // Number of errors at each time point
fill: false,
borderColor: 'rgba(255, 99, 132, 1)',
tension: 0.1,
},
],
}; return (
<div className="chart">
<h3>Error Rates</h3>
<Line data={chartData} />
</div>
);
};export default ErrorRateChart;
2.4 Example Metrics Service (metricsService.js)
import axios from 'axios';
export const getMetrics = async () => {
try {
const response = await axios.get('http://<BACKEND_URL>/api/metrics');
return response.data;
} catch (error) {
console.error('Error fetching metrics:', error);
return {
errorRates: [],
dbPerformance: [],
trafficUsage: [],
};
}
};
3. Frontend Metrics Visualization Libraries
You can use charting libraries in ReactJS for visualizing metrics, such as:
Chart.js (used in the example above)
- Provides flexible and beautiful visualizations, such as bar, line, and pie charts.
Recharts:
- React-specific charting library with a focus on simplicity and responsiveness.
Victory:
- Another React-specific charting library for building interactive visualizations.
D3.js:
- For complex and custom visualizations, though it might require more setup and understanding of SVGs.
Chart.js Example for Line Graph (for error rates or traffic)
npm install react-chartjs-2 chart.js
In your React component, you can import react-chartjs-2 and use its Line chart component as demonstrated in the ErrorRateChart.js example.
4. Backend API for Metrics
Your backend API (e.g., built with Spring Boot) should expose endpoints that provide the required metrics data. Here’s an example Spring Boot controller:
MetricsController.java
@RestController
@RequestMapping("/api/metrics")
public class MetricsController {
@Autowired
private MetricsService metricsService; @GetMapping
public ResponseEntity<Map<String, Object>> getMetrics() {
Map<String, Object> metricsData = metricsService.getMetricsData();
return ResponseEntity.ok(metricsData);
}
}
MetricsService.java
@Service
public class MetricsService {
public Map<String, Object> getMetricsData() {
Map<String, Object> metricsData = new HashMap<>();
metricsData.put("errorRates", getErrorRates());
metricsData.put("dbPerformance", getDbPerformance());
metricsData.put("trafficUsage", getTrafficUsage());
return metricsData;
} private List<ErrorRate> getErrorRates() {
// Logic to fetch error rates from logs or databases
} private List<DbPerformance> getDbPerformance() {
// Logic to fetch database performance metrics
} private List<TrafficUsage> getTrafficUsage() {
// Logic to fetch traffic/resource usage
}
}
This data could be fetched from a database, logs, or monitoring tools like Prometheus or Grafana, and can be serialized into JSON and sent to the frontend.
5. Deployment and Scalability Considerations
Real-time Data: If you need real-time updates on the dashboard, consider using WebSocket's to push updates to the React frontend or Server-Sent Events (SSE).
Data Caching: Use caching mechanisms (e.g., Redis) to avoid fetching large datasets repeatedly.
Scalability: Ensure your backend APIs are optimized to handle large amounts of traffic, and use load balancing if necessary.
Step 6: Going Beyond Basics
1. AWS Resource Logs Integration
Purpose: AWS Resource Logs provide real-time insights into the health and performance of your cloud infrastructure. By integrating AWS CloudWatch logs and metrics, you can enrich your platform with vital cloud-based data.
Steps to Integrate AWS Resource Logs:
Set Up AWS CloudWatch:
Enable CloudWatch Logs for your AWS services (EC2, Lambda, S3, etc.) to collect logs and metrics.
Set up CloudWatch Alarms to notify you of any anomalies or errors in the logs.
Fetching CloudWatch Logs:
Use the AWS SDK for Java (or the appropriate SDK for your backend) to retrieve CloudWatch logs.
API call example for fetching logs:
import com.amazonaws.services.logs.AWSLogs;
import com.amazonaws.services.logs.AWSLogsClientBuilder;
import com.amazonaws.services.logs.model.*;
public List<LogEvent> fetchLogs(String logGroupName) {
AWSLogs client = AWSLogsClientBuilder.defaultClient();
FilterLogEventsRequest request = new FilterLogEventsRequest()
.withLogGroupName(logGroupName)
.withLimit(50);
FilterLogEventsResult result = client.filterLogEvents(request);
return result.getEvents();
}
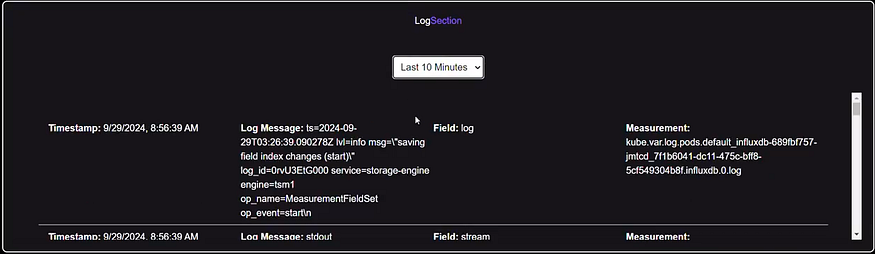
Display Logs in the Dashboard:
- On the frontend, create components to display the logs in real time. For example, using React and a library like React Table for showing log entries.
Example Component for Displaying Logs:
import React, { useState, useEffect } from 'react';
import { Table } from 'react-table';
import { fetchCloudWatchLogs } from './services/awsLogsService';
const AwsLogsDashboard = () => {
const [logs, setLogs] = useState([]);
useEffect(() => {
const fetchLogs = async () => {
const data = await fetchCloudWatchLogs();
setLogs(data);
};
fetchLogs();
}, []);
const columns = [
{ Header: 'Timestamp', accessor: 'timestamp' },
{ Header: 'Log Message', accessor: 'message' },
// Add more columns as needed
];
return (
<div>
<h2>AWS Resource Logs</h2>
<Table data={logs} columns={columns} />
</div>
);
};
export default AwsLogsDashboard;
2. Alerting System
Purpose: Alerting notifies users about critical events (such as errors, performance degradation, or resource limits being reached) in real-time.
Steps to Implement an Alerting System:
Backend:
Integrate AWS CloudWatch Alarms to set thresholds for your resources (e.g., high CPU usage, low memory, errors in logs).
Trigger these alarms to notify your backend, which can then communicate with the frontend.
AWS CloudWatch Alarm Configuration:
import com.amazonaws.services.cloudwatch.AmazonCloudWatch;
import com.amazonaws.services.cloudwatch.AmazonCloudWatchClientBuilder;
import com.amazonaws.services.cloudwatch.model.*;
public void createAlarm() {
AmazonCloudWatch cloudWatch = AmazonCloudWatchClientBuilder.defaultClient();
PutMetricAlarmRequest alarmRequest = new PutMetricAlarmRequest()
.withAlarmName("HighCPUUsage")
.withComparisonOperator(ComparisonOperator.GreaterThanThreshold)
.withEvaluationPeriods(1)
.withMetricName("CPUUtilization")
.withNamespace("AWS/EC2")
.withPeriod(60)
.withStatistic(Statistic.Average)
.withThreshold(80.0)
.withActionsEnabled(true)
.withAlarmActions("arn:aws:sns:region:account-id:my-topic");
cloudWatch.putMetricAlarm(alarmRequest);
}
Frontend (React):
Set up a WebSocket connection or Server-Sent Events (SSE) to listen for real-time alerts.
Display an alert in the UI when a critical event is triggered (e.g., high CPU usage, error spikes).
Example Code for Alert Notification:
import React, { useState, useEffect } from 'react';
const AlertComponent = () => {
const [alerts, setAlerts] = useState([]);
useEffect(() => {
const eventSource = new EventSource('http://<BACKEND_URL>/api/alerts');
eventSource.onmessage = (event) => {
const newAlert = JSON.parse(event.data);
setAlerts((prevAlerts) => [...prevAlerts, newAlert]);
};
return () => {
eventSource.close();
};
}, []);
return (
<div>
<h2>System Alerts</h2>
{alerts.length > 0 ? (
<ul>
{alerts.map((alert, index) => (
<li key={index} className={`alert ${alert.type}`}>
{alert.message}
</li>
))}
</ul>
) : (
<p>No alerts at the moment</p>
)}
</div>
);
};
export default AlertComponent;
3. Predictive Analysis Using Machine Learning
Purpose: Predictive analysis helps forecast system performance, resource usage, and potential failures, enabling proactive actions before problems arise.
Steps to Implement Predictive Analysis:
Data Collection:
Collect historical metrics such as CPU usage, error rates, traffic volumes, etc., over a significant period.
Store these in a database or time-series database like InfluxDB.
Training a Machine Learning Model:
Use a machine learning framework like TensorFlow, Scikit-learn, or PyTorch to create models that can forecast metrics.
Example: Linear Regression or Time Series Forecasting (e.g., ARIMA or LSTM for sequential data).
Python Example (using Scikit-learn):
from sklearn.linear_model import LinearRegression
import numpy as np
# Example of training a simple model to predict CPU usage
data = np.array([[1, 50], [2, 55], [3, 60], [4, 65]]) # [hour, CPU Usage]
X = data[:, 0].reshape(-1, 1) # Hour
y = data[:, 1] # CPU usage
model = LinearRegression()
model.fit(X, y)
# Predict CPU usage for hour 5
prediction = model.predict([[5]])
print(f"Predicted CPU usage at hour 5: {prediction}")
Backend Integration:
Expose the machine learning model through an API endpoint.
Use Flask or FastAPI in Python to serve the model predictions.
Example FastAPI Endpoint for Predictions:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class PredictionRequest(BaseModel):
hour: int
@app.post("/predict")
def predict(request: PredictionRequest):
prediction = model.predict([[request.hour]])
return {"predicted_cpu_usage": prediction[0]}
Frontend Integration:
On the React frontend, request predictions from the backend and visualize the forecasted data.
Example of Fetching and Displaying Predictions:
import React, { useState } from 'react';
const PredictiveDashboard = () => {
const [prediction, setPrediction] = useState(null);
const fetchPrediction = async (hour) => {
const response = await fetch('http://<BACKEND_URL>/predict', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ hour }),
});
const data = await response.json();
setPrediction(data.predicted_cpu_usage);
};
return (
<div>
<h2>Predictive Performance Analysis</h2>
<button onClick={() => fetchPrediction(5)}>Predict for Hour 5</button>
{prediction && <p>Predicted CPU Usage: {prediction}%</p>}
</div>
);
};
export default PredictiveDashboard;
The Impact of Innovation

At the heart of every successful hackathon is the drive for innovation, and our team’s experience in designing a state-of-the-art observability platform is a perfect example of this. A well-crafted observability solution is not just a technical fix — it serves as a force multiplier, helping teams manage intricate systems with ease. During the hackathon, we took on the challenge of building this innovative platform, and through this journey, we not only pushed the boundaries of technology but also enhanced our skills and problem-solving abilities. Here’s a closer look at the impact this innovation has had on us as participants:
Hands-On Expertise with Kubernetes, Log Management, and Full-Stack Development
In the hackathon, we dove deep into the world of Kubernetes, log management, and full-stack development, each of which played a pivotal role in the success of our observability platform. Kubernetes, a powerful tool for orchestrating containers, enabled us to streamline the deployment and scaling of our system. We learned to harness its capabilities to ensure our platform was both efficient and resilient, crucial for dealing with the complex environments we aimed to monitor.
Log management was another critical aspect of our solution. We tackled the challenge of collecting, storing, and analyzing logs in real-time to ensure we could quickly identify and address issues within the system. This aspect of the project not only improved our technical acumen but also made us realize the importance of clear, structured logging in production environments, especially when dealing with large-scale applications.
Additionally, we took on both frontend and backend development, ensuring that our observability platform was not just functional but also user-friendly. We gained invaluable experience in building intuitive user interfaces that allow teams to visualize logs, monitor metrics, and trace transactions effectively. This full-stack approach helped us understand the end-to-end process of building robust systems, preparing us for future challenges in web and software development.
Problem-Solving Skills for Tackling Real-World Challenges
The hackathon environment itself provided a fast-paced, high-pressure setting that pushed our problem-solving skills to the limit. We encountered several production-level challenges that tested our creativity, adaptability, and resourcefulness. From debugging complex issues to optimizing system performance under tight deadlines, we learned to think on our feet and find solutions that not only met but exceeded the expectations of the challenge. These problem-solving skills are now a core part of our toolkit, allowing us to approach any future project with a sense of confidence and capability.
Working under the constraints of a hackathon also made us realize the importance of time management and prioritizing tasks, ensuring that we could focus on the most crucial aspects of the platform while delivering a high-quality solution within the given time frame.
A Portfolio Project Showcasing Depth and Breadth of Knowledge
By the end of the hackathon, we were left with a complete observability platform that not only demonstrated our technical skills but also stood as a testament to our ability to innovate and solve real-world problems. This project has become a significant addition to our portfolios, highlighting both our in-depth understanding of observability tools and technologies and our ability to integrate them into a cohesive, functional system.
This portfolio piece is more than just a project — it’s a reflection of our growth as developers, problem-solvers, and innovators. It showcases our ability to work collaboratively, tackle challenges head-on, and deliver a working solution that meets real-world needs.
Conclusion: Empowering Future Innovators

The Log Strata Infra Monitor Challenge is far more than just a hackathon — it’s a chance to redefine observability on your own terms. Throughout the journey, we didn’t just focus on solving technical problems; we worked to shape the future of cloud monitoring. By collecting, processing, and visualizing data in innovative ways, we were able to build a platform that transforms raw information into actionable insights.
This hackathon has been an incredible opportunity for us to push the boundaries of what’s possible in the realm of observability. It’s not just about mastering tools and technologies; it’s about unleashing creativity, exploring new approaches, and contributing to the evolution of cloud systems. We’re not just participants in a challenge — we’re active creators of the next generation of observability platforms.
So, as we wrap up this experience, we’re inspired to continue rolling up our sleeves and pushing forward. The work we’ve done here lays the foundation for future innovations, and we’re excited to see how this journey unfolds as we continue building platforms that drive meaningful insights and transformation in the world of cloud monitoring.
Thank you for taking the time to read my blog. Your feedback is immensely valuable to me. Please feel free to share your thoughts and suggestions.

